
ImageBind,由Facebook Research开发,是一个跨模态的联合嵌入学习工具。它的设计目标是能够同时处理并理解六种不同的模态:图像、文本、音频、深度、热量和IMU(惯性测量单元)数据。这种广泛的模态兼容性使得ImageBind能够处理和解析大量的输入数据,从而为许多新兴应用提供支持。
跨模态检索
ImageBind的一个关键特性是跨模态检索。这意味着,不论是图像、文本、音频,还是其他类型的输入,ImageBind都能够有效地检索相关的信息。例如,用户可以输入一段描述,ImageBind就能从数据库中找出与之相关的图像或音频。同样,用户也可以输入一张图片,ImageBind就能找出相关的文本描述或者音频片段。
模态运算
另一项特性是模态运算,即ImageBind可以对不同模态的数据进行“加减法”。这不仅仅是指数据量的增减,更重要的是,它能够理解和解析不同模态之间的关系。例如,给定一个图片和一个文本描述,ImageBind可以生成一个新的图片,它融合了原始图片的视觉特征和文本描述中的语义信息。
跨模态检测和生成
ImageBind也能进行跨模态的检测和生成。它可以识别出不同模态的数据中的相同特征,例如在一段音频和一张图片中识别出相同的主题。此外,它也能够根据给定的输入生成新的、与输入相关的输出。例如,它可以根据一段文本生成一张相关的图片,或者根据一张图片生成一段相关的音频。
结论
总的来说,ImageBind是一个开创性的工具,它将多模态理解的能力提升到了一个新的水平。它可以处理和解析大量的输入数据,使得许多新兴应用得以实现。无论是跨模态检索、模态运算,还是跨模态检测和生成,ImageBind都能够提供强大的支持。随着这种工具的不断发展和优化,我们期待看到更多的创新应用和突破性的研究。

MetaAI,这位曾在元宇宙和Web 3.0中磕破头破血流的少年,如今已在AIGC领域挥舞起开源的利剑,展现出强大的实力。
在过去的几个月里,MetaAI已经在GitHub上开源了多个实用的项目:
- Segment Anything (SAM),一个可以自动分割图片或视频中所有物体的工具,一键自动分割,使图像编辑变得更为便捷。
- DINOv2,这个无需微调的工具可以通过自监督学习获取视觉特征,直接推动了计算机视觉技术的发展。
- Animated Drawings,这个工具利用AI技术,可以快速地为绘画作品添加动画效果。
这些只是冰山一角。
今天,MetaAI又发出了重大消息,正式宣布了ImageBind的开源。这个工具可以让模型跨越6种不同的模态(图像、文本、音频、深度、温度和IMU数据)进行联动交流。
这里附上扎克伯格前几天在Facebook上发布的一个视频,让你们可以直观地感受到ImageBind的强大功能:
AI模型每增加一种模态的支持,它的能力就会更接近人类。
我们能看到繁华的街道、听到马路上的鸣笛声、感受到炎炎夏日的热度,这些都是源于我们与生俱来的感官能力。视觉、听觉、嗅觉和味觉等感知能力使我们能更好地与世界互动。
如果我们想让AI更接近人类的能力,那就需要我们赋予它更多的感知世界的能力。
在过去,要在各个模态之间建立关联,需要同时维护和训练多份数据。现在,有了ImageBind,我们可以直接从音频生成图像,例如,让AI听一段海浪声,它就能直接生成出海洋的图像,这大大节省了训练成本。
从某种角度来看,AI已经开始像人类一样,根据听到的声音脑补出画面。
更为了不起的是,ImageBind还内置了3D感知和IMU传感器功能,能够测量加速度和旋转运动,让AI能够更身临其境地感受我们的物理世界的变化。
此外,ImageBind还提供了一种新型的记忆检索方式,让AI能够直接使用文本、音频和图像的组合数据,直接搜索图片、视频、音频文件或文本消息。
通过这种方式,我们可以使AI生成的内容质量更高。例如,在视频剪辑领域,AI可以根据我们提供的声音、图像和文本,直接搜索出匹配度更高的视频片段,实现真正的一键视频剪辑功能!
在传统的AI系统中,每个模态都有自己的嵌入(数据在机器学习中的关系数字向量),这使得不同模态之间的交互和检索变得困难,我们无法直接根据音频来准确检索出相关的图像和视频。
但ImageBind解决了这个问题。它通过将六种模态的嵌入对齐到一个公共空间,实现了跨模态的检索。
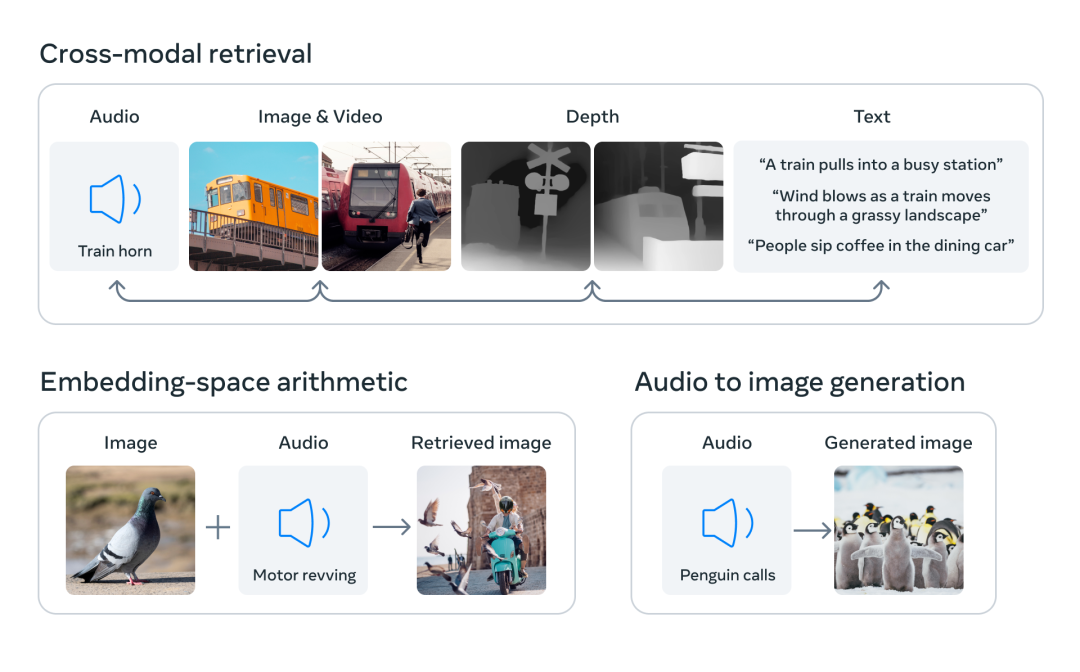
作为一款多模态模型,ImageBind集成了我之前提到的SAM和DINOv2,从而进一步增强了其能力。
将各个模态连接在一起,构建一个无缝交流的桥梁,这就是ImageBind实现的核心功能。
MetaAI之前开发的Make-A-Scene工具,可以通过文本生成图像。现在,借助ImageBind,它甚至可以直接通过声音生成图像。这使得AI能够更深入地理解人类的情绪,了解我们的喜怒哀乐,并据此为我们提供更好的服务。
同时,由于ImageBind的跨模态交流能力,每一个模态的提升都会带动另一个模态的进步,形成一种雪球效应。
为了证实这一点,MetaAI的技术团队进行了基准测试,发现ImageBind在音频和深度方面的表现明显优于其他专业模型。这种优势来自于AI从其他模态中吸取和总结的经验。
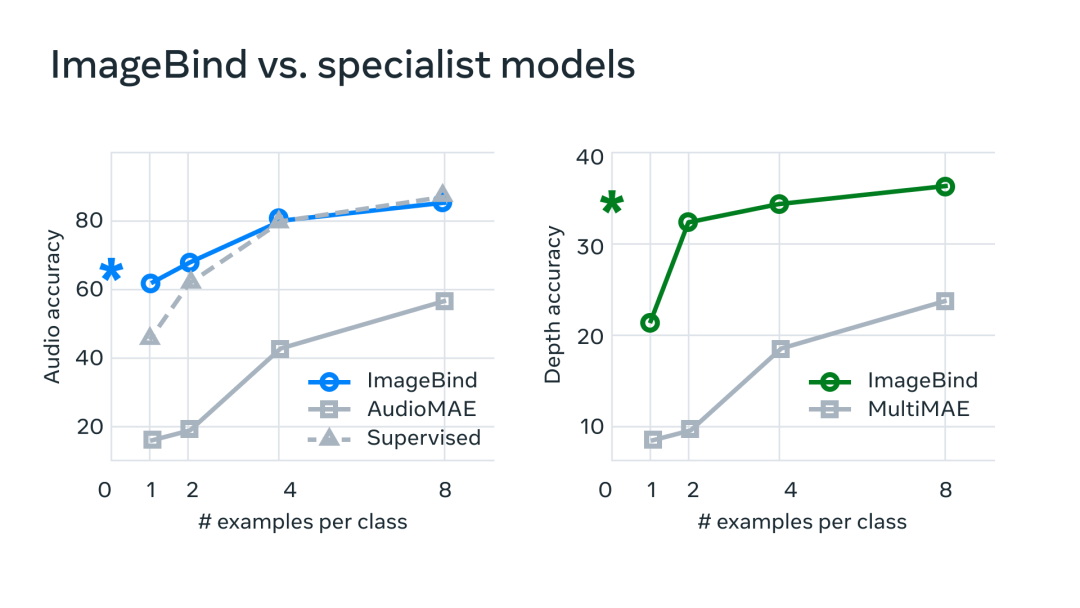
未来可以预见的是,视频剪辑将变得越来越简单。当你举起手机,录制一段海边日落的视频时,AI将能够根据视频内容自动生成文案和字幕,并匹配上合适的背景音乐。甚至,AI甚至可能通过一首歌,直接为歌手生成一段音乐视频。
在VR和AR游戏中,用户也可以通过多种方式,如语音、手势和头部动作等,与游戏角色进行交互,从而增强游戏的互动性和沉浸感。
在医疗领域,医生可以通过语音、图像等多种方式收集患者的病情信息,然后通过机器学习等技术进行处理和分析,以更准确地得出诊断结果和治疗方案。
尽管目前ImageBind只包含6种模态,但随着更多感官功能的集成,如嗅觉和触觉,AI模型的能力将变得更为强大,从而带来AIGC行业的翻天覆地的变化。
ImageBind的出现将为AIGC技术带来更广泛的应用场景,更多有趣且实用的AI项目也将接踵而至。
我们离通用人工智能的到来,又近了一步。
GitHub:
此处内容需要权限查看


