
最近,谷歌的研究人员在预印本平台 arXiv 发表了一篇题为:HeAR — Health Acoustic Representations 的研究论文。他们开发了一种可以通过评估咳嗽和呼吸等声音来帮助检测和监测健康状况的人工智能工具。
这个人工智能(AI)系统在数百万个人类声音的音频剪辑样本上进行了训练,将来可能帮助医生用来诊断包括COVID-19和肺结核在内的肺部疾病,并评估一个人的肺功能。

实际上,这并不是第一次探索将声音作为疾病的生物标志物。在COVID-19大流行期间,南达科他大学的研究人员就曾在 PeerJ Computer Science 期刊发表综述论文【2】,提出可以通过一个人的咳嗽来检测呼吸道疾病。系统分析了通过人工智能工具分析咳嗽声音以进行COVID-19筛查的研究。
谷歌此次开发的这款AI系统名为HeAR(Health Acoustic Representations),其新颖之处在于其训练所用的海量数据集,以及它可以被微调以执行多种不同任务。研究团队表示,现在判断HeAR是否会成为商业产品还为时过早。目前的计划是让感兴趣的研究人员访问该模型,以便他们可以在自己的研究中使用它。他们的目标是这款AI系统能够刺激这个新兴领域的创新。
如何训练模型?
在这个领域开发的大多数人工智能工具都是通过音频记录进行训练的,例如咳嗽的录音,这些录音与发出声音的人的健康信息配对。例如,这些录音片段可能会被标记为录音时这个人患有支气管炎。这些人工智能工具通过一个称为监督学习(Supervised Learning)的训练过程,将声音的特征与数据标签关联起来。
而在这项研究中,谷歌的研究人员使用了自监督学习(Self-supervised Learning),使用的是未标记的数据,通过一个自动化过程,从公开可用的YouTube视频中提取了超过3亿个咳嗽、呼吸、清喉咙和其他人类声音的短声音片段。每个片段被转换成声音的视觉表示——频谱图。然后研究团队封锁了频谱图的片段,以帮助模型学习预测缺失的部分。这类似于聊天机器人ChatGPT的大型语言模型在经过无数人类文本示例的训练后,学会预测句子中的下一个单词。使用这种方法,研究团队创建了一个基础模型,这个模型可以适应许多不同任务。
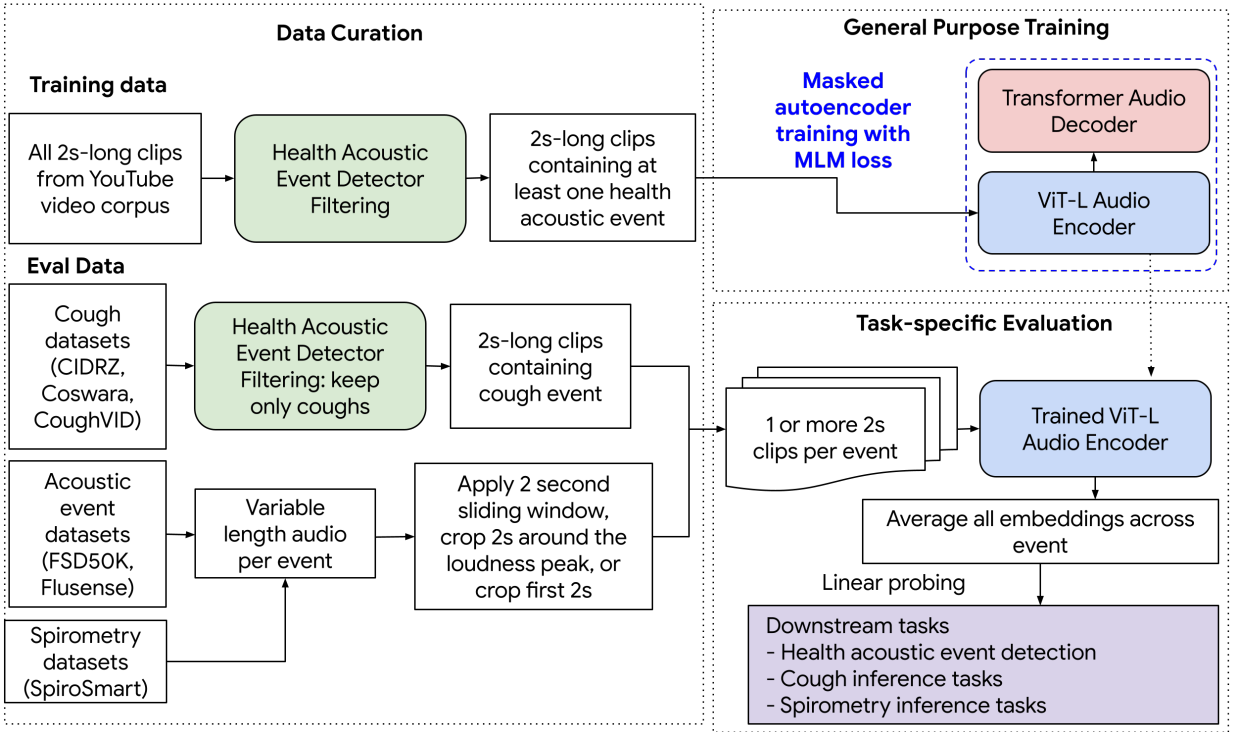
高效的学习者
谷歌的研究人员将HeAR模型用于检测COVID-19、肺结核和个人是否吸烟等特征。由于该模型是在如此广泛的人声上进行训练的,要想对其进行微调,研究团队只需要向其提供非常有限的带有这些疾病和特征的数据集。
得分为0.5代表HeAR模型表现不优于随机预测,得分为1代表HeAR模型每次都能做出准确预测,HeAR在COVID-19检测方面的得分为0.645和0.710,这取决于测试的数据集,对于肺结核检测,得分为0.739。
由于HeAR模型的原始训练数据非常多样化,具有不同的音质和人类来源,这也意味着其训练结果具有普遍性和可靠性。
声学已经存在了几十年,健康声学(或叫做音频组学)很有前途,现在有了人工智能和机器学习,就有能力同时收集和分析大量数据。将声音作为追踪健康的生物标志物,这不仅在疾病诊断方面有巨大的潜力,而且在疾病筛查和监测方面也有巨大的潜力。因为我们不能每周都重复扫描或活检,因此,声音可以作为疾病监测的一个非常重要的生物标志物,而且它还具有非侵入性、成本低等优势。
论文链接:
https://arxiv.org/abs/2403.02522https://peerj.com/articles/cs-958/


