
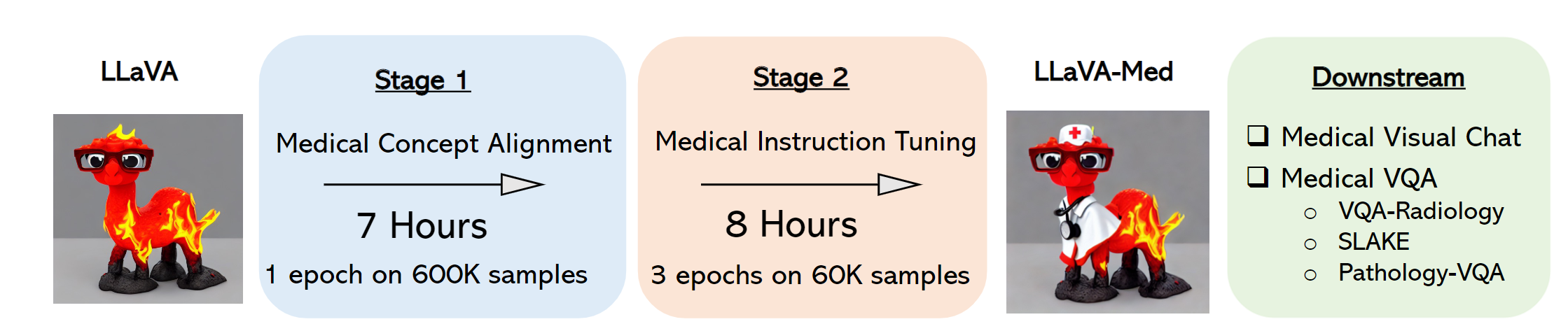
LLaVA-Med,全称为Large Language and Vision Assistant for BioMedicine(大型生物医学语言与视觉助手),是微软开发的一个项目,旨在构建具有GPT-4级能力的大型语言和视觉模型,特别是在生物医学领域。
LLaVA-Med的初期使用的是通用领域的LLaVA模型,然后通过课程学习方式连续训练,首先进行生物医学概念对齐,然后进行全面的指令调优。该项目在标准的视觉对话和问题回答任务上进行了评估。数据、代码和检查点的使用和许可仅限于研究用途,数据集采用CC BY NC 4.0许可,仅允许非商业用途。
LLaVA-Med数据集包括生物医学多模态指令跟随数据,涵盖多个领域,每个领域显示一张图片。LLaVA-Med的性能与仅语言的GPT-4模型的性能进行了比较,后者被视为性能上限。LLaVA-Med模型也在已建立的Medical QVA数据集上进行了评估。
总的来说,LLaVA-Med是微软在AI领域的一项重要研究,它的开发和应用将在生物医学领域开辟新的可能性,并为未来的医疗诊断和治疗提供更多的智能化选择
https://github.com/microsoft/LLaVA-Med
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


